

Kanishk Barhanpurkar, UG Student, Department of Computer Science & Engineering, SAIT, Bengaluru, Karnataka, India
Ajay Joshi, Assistant Professor, Shri Vaishnav Institute of Textile Technology, SVVV, Indore, Madhya Pradesh, India
Shyam Barhanpurkar,Assistant Professor, Shri Vaishnav Institute of Textile Technology, SVVV, Indore, Madhya Pradesh, India
Abstract
Social media especially Twitter is providing a large volume of expression and opinions, where users discuss various events, services, and products. It can be used for different models and interpret reviews on newly launched devices. Entrepreneurs are in continuous need of feedback about their services to improve the quality and quantity. However, due to the bulk amount of data, it’s difficult to detect the consumer’s opinions. This article considers the problems with Twitter data for sentiment analysis. Additionally, it implements the text mining and document-based sentiment on the preprocessed Twitter data through machine learning techniques, Naïve Bayes and lexicon dictionary. Sentimental analysis is an application of textual analysis under the Natural-processing language domain. In this article, we have implemented many machine learning techniques to know about consumer feedback on apparel industry.
Keywords: Apparel-Industry, Data-preprocessing, Sentimental-analysis, Support Vector Machine, Textile-industry.
1. INTRODUCTION
In 2018, on an average, around 336 Million tweets per month were tweeted on Twitter platform. In the knowledge resources, it is statistically verified that 71% of the internet has been used through social media by the consumers. Studies show that more than half of customers prefer to read the other’s comments about those products before purchasing. Thus public opinions are the best source of feedback for business stakeholders about their products and services which enable them to redesign the quality factor and disclose the opportunity of a new business. The social network like Twitter and Facebook provided important marketing, selling, branding, and promotional chances to the brands. It’s a mathematically procedural study of people’s thoughts and opinions which can be positive or negative about any product or event through the natural language processing namely as ‘sentiment analysis’. Sentiment analysis is correlated with text mining or data mining. The basic purpose of sentiment analysis is to guarantee the polarity of natural language by performing supervised and unsupervised classification. Recently available sentiment analysis techniques are useful for political predictions, marketing strategy, e-commerce, and brand reputation management.
It will illustrate the relationship between the consumers and the apparel enterprise. In our work study, preprocessing step has been taken to achieve the better analysis results. The Bernoulli Naïve Bayes algorithm has been used with the lexicon dictionaries. Moreover, this study is a document-based approach and extracts the polarity from the tweets. This comparative study will assist the new researcher to analyze the social media for the sentiment detection. We are also implementing textual analysis using “bag-of-word” approach.
2. ABOUT SENTIMENT ANALYSIS
Sentiments are subjective to the point of interest. We are required to formulate what kind of features will decide forthe sentiment it embodies. In the programming model, a sentiment we refer to is the class of entities that the person performing emotion analysis wants to find in the tweets. The dimension of the sentiment class plays a crucial factor indeciding the propriety of the model. For example, we can have two-class tweet sentiment classification (positive andnegative) or three class tweet sentiment classification (positive, negative and neutral). But in this paper, we have described system on three-class sentiment analysis. Sentiment analysis approaches can be broadly categorized into two classes, lexicon-based and machine-learning-based. Lexicon based approach is unsupervised as it proposes to perform analysis using lexicons and a scoring method to evaluate opinions. The basic steps for performing sentiment analysis includedata collection, pre-processing of data, feature extraction, selecting baseline features, sentiment detection and performing classification on different data-set either using simple computations or forming representations.
3. HOW SENTIMENTAL ANALYSIS CAN BE USED IN TEXTILE AND APPAREL INDUSTRY?
The fashion and apparel supply chain is a complex network of various actors designated worldwide. It deals with a diversity of raw materials: fiber, yarn, fabric, dyestuff, and other chemicals, and the related processes are broadly classified into four stages: design, fabric production and apparel production. The designers employed by retailers are responsible for creating collections based on the current market and trend analysis. In most scenarios, retailers do not own any production house and play an important role to bring the products into the market. However, in the past decade, with the advent of e-commerce, the definition of Business-to-Business (B2B) and Business-to-Customer (B2C) has evolved. Therefore, it has become important for the industry to adapt to this change and create new business strategies. It has also become vital to give a comprehensive demarcation between B2B and B2C, and how machine learning can help in combating problems at these segments.Machine Learning Algorithms can be implemented in sentimental analysis related for customer review and can also be used in B2B and B2C involved. By collecting tweets for a particular agenda or product related to textile industry and apparel industry, the customer review can be analyzed in form of three categories-positive, negative and neutral. In the brief, this model will be used by business analyst or other officials to analyze the review over accuracy of machine learning techniques on a particular agenda or product launched by any companies.
4. METHODOLOGY FOR IMPLEMENTING PROCESS ON APPAREL INDUSTRY DATA-SET
The process of sentimental analysis can be carried from data from the Twitter social media-networking. In this system we
are using twitter data set which undergoes various type of pre-processing. For data pre-processing many differenttechniques were used to make data feasible according to the requirements. The complete system divided in three processesis as follows-
Tweet Collection
ii. Pre-processing of tweets
iii. Twitter Sentimental analysis using Python
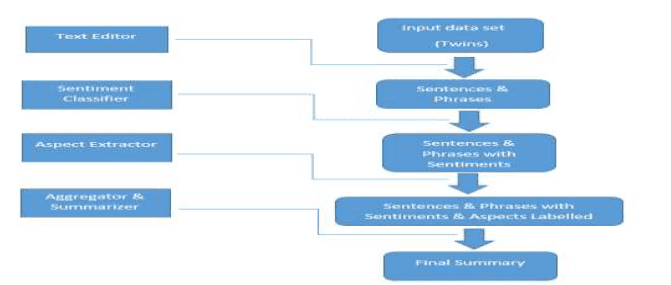
Fig.1 General Methodology for data analysis
4.1 Tweet Collection using TweetPy API
Tweet collection involves gathering of appropriate tweets about the particular area of interest. The tweets are collectedusing Twitter’s streaming API or any other mining tool for desired time period of analysis. The form of the retrieved textis converted into required file format. The dataset is collected for the efficiency of the model. The division of dataset intotraining and testing set is also a deciding factor. We also used a word-bag which contains different words which arecategorized into positive, negative and neutral words. They are arranged in the alphabetical order on which basis thedecision would be made whether it can be categorized into negative tweet, positive tweet or neutral tweet.
4.2 Pre-processing of tweets
The preprocessing of the data is one of the necessary aspects as it decides the over-all efficiency of the system. It alsoinvolves syntactical correction of the random twitter data provided and generated using Twitter system. The steps involved should aim for making the data more machines readable in order to reduce ambiguity in feature extraction.
- Elimination of re-tweets- In the twitter system, the main problem is the removal of retweets because re-tweetsleads to redundancy of data.
- Transfiguring upper case to lower case: In case, we are using case sensitive analysis, we can use a single wordfor two different meaning. An effective analysis mustn’t provide such misgivings to the model.
- Stop word elimination: Stop words that don’t affect the meaning of the tweet is removed. It uses the WEKAmachine learning package for this purpose, which checks each word from the text against a dictionary.
- Twitter feature deletion: User names and URLs are not important from the perspective of future processing; hencetheir presence is futile. All usernames and URLs are converted to generic tags or removed.
4.3 Implementation of Sentimental Analysis for Apparel Industry using Machine Learning Algorithms
An algorithm, Naïve Bayes (NB) has been used for the classification of emotions and polarity at each document based on the sentiment analysis. The NB algorithm is a probabilistic model which uses Bayes’ Theorem to solve the classification problems by assuming the data attributes as an independent. NB classifier trained by processed data set which is annotated by three classes: Positive, negative, and neutral tweets. In Machine Learning domain, the natural language processing tools were used to calculate the score for sentiment analysis. The NB polarity classifier is used to get the better engagement between the tweet words and lexicon words. A Support Vector Machine (SVM) is a discriminative classifier formally defined by a separating hyperplane. In other words, given labeled training data (supervised learning), the algorithm outputs an optimal hyperplane which categorizes new examples. In two dimensionalspaces this hyperplane is a line dividing a plane in two parts where in each class lay in either side.Linguistic theories generally regard human languages as consisting of two parts: a lexicon, essentially a catalogue of a language’s words (it’s words tock); and a grammar, a system of rules which allow for the combination of those words into meaningful sentences. The lexicon is also thought to include bound morphemes, which cannot stand alone as words. We have implemented all this system using Python and its libraries such as NumPy, Pandas, Scikit-learn and NLTK library.
5. Data-set extracted from Twitter
We have used Twitter’s streaming API for creating a dataset consisting of around 6,500 tweets. Then the above described
methodology is implemented to get the required output. During the first step, that is generating a data-set consisting oftweets are done using Twitter API. Then conversion of data is done by performing some functions using some standardand most recommended libraries. Some major processes were carried out in this step such as the conversion of the upper case to lower case. Apart from this, the removal of handles, hashtags, emoticons and repeated characters were done inthis step. After cleaning, we go for sentimental analysis using Python and its libraries. We also used bag-of-wordsfor segregating positive, negative and neutral words. Additionally, the data set will be segregated in positive, negativeand neutral tweets. The result for every tweet separately can be determined using this methodology.
7. RESULTS
Using Twitter API, tweets have been collected. A random dataset is created for around 8,500 tweets on the current apparel industry. After the data-set hasbeen processed through the methodology implemented we get result in form of distinguished tweets as positive tweets,negative tweets and neutral tweets. And every tweet is distinguished as different type of sentimental tweet as it is a three class model of textual analysis. In the form of result, we obtain all types of tweets whether these tweets are related to anyfield or any other domain. This method can be implemented in any particular field related to business, any technical sector may be related to topic. In general, it can be any distinguished as an interdisciplinary domain of computer science that deals with more complex data-sets as feature selection will become more important.
| S.No. | Classifier | Accuracy |
| 1 | DAN2 | 86.06% |
| 2 | SVM | 85.00% |
| 3 | Bayesian Logistic Regression | 74.84% |
| 4 | Naïve Bayes | 66.24% |
| 5 | Random Forest Classifier | 87.50% |
| 6 | Maximum Entropy | 90.0% |
Table 1: Average accuracies of different models
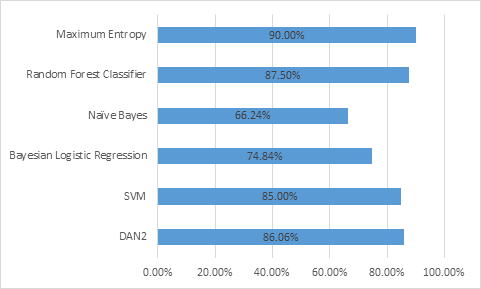
Fig. 2 Accuracy for various machine-learning algorithms
8. CONCLUSIONS & FUTURE SCOPE
Twitter sentiment analysis comes under the category of text and opinion mining. It focuses on analyzing the sentiments of
the tweets and feeding the data to a model in order to train it and then check its accuracy, so that we can use this model for
future use according to the results. In comprises of steps like data collection, text pre-processing, sentiment detection,sentiment classification. This research topic has evolved during the last decade with models getting the efficiency of nearly 85%-90%. But it still dearth the aspect of multiplicity in the data. Along with this it has a lot of application issues with the slang used and the short forms of words. On increasing number of classes, the overall accuracy for sentimental analysis decreases. Hence, we suggest to use 3-class model for sentiment analysis for the textile industry to obtain opinion about different new trends and products that are used in industry and has a very bright scope for development in future. Also, it can be implemented in following fields are as follows-
- Business: Corporations can make use of this research for gathering public result related to their product and goods.From the business’s perspective, the investigation of the target audience is imperative for making out the ratingsof their products. Hence Twitter can serve as an upright platform for data collection and analysis to conclude clientsatisfaction.
- Politics: Majority of tweets on Twitter are related to politics. Due to Twitter’s extensive use, many politicians arealso aiming to connect to society through it. People post their agreement or disagreement towards governmentpolicies, actions, elections, debates etc. Hence inspecting data from it can help is in influential public view.
- Sports Events: Sports involve many events, tournaments, meetings and some controversies too. Many people areexcited about sports followers and follow their favorite players present on Twitter. These people frequently tweetabout different sports-related occasions.
9. REFERENCES
[1] David Zimbra, M. Ghiassi and Sean Lee, “Brand-Related Twitter Sentiment Analysis using Feature Engineering and the Dynamic Architecture
for Artificial Neural Networks”, IEEE 1530-1605, 2016.
[2] Varsha Sahayak, Vijaya Shete and Apashabi Pathan, “Sentiment Analysis on Twitter Data”, (IJIRAE) ISSN: 2349-2163, January 2015.
[3] PeimanBarnaghi, John G. Breslin and ParsaGhaffari, “Opinion Mining and Sentiment Polarity on Twitter and Correlation between Events and
Sentiment”, 2016 IEEE Second International Conference on Big Data Computing Service and Applications.
[4] Mondher Bouazizi and TomoakiOhtsuki, “Sentiment Analysis: from Binary to Multi-Class Classification”, IEEE ICC 2016 SAC SocialNetworking, ISBN 978-1-4799-6664-6.
[5] Nehal Mamgain, Ekta Mehta, Ankush Mittal and Gaurav Bhatt, “Sentiment Analysis of Top Colleges in India Using Twitter Data”, (IEEE)ISBN -978-1-5090-0082-1, 2016.
[6] Shi Yuan, Junjie Wu, Lihong Wang and Qing Wang, “A Hybrid Method for Multi-class Sentiment Analysis of Micro-blogs”, ISBN- 978-1-5090-2842-9, 2016.
[7] Apoorv Agarwal, BoyiXie, Ilia Vovsha, Owen Rambow and Rebecca Passonneau, “Sentiment Analysis of Twitter Data” Proceedings of theWorkshop on Language in Social Media (LSM 2011), 2011.
[8] Neethu M S and Rajasree R, “Sentiment Analysis in Twitter using Machine Learning Techniques”, IEEE –31661, 4th ICCCNT 2013.
[9] Aliza Sarlan, ChayanitNadam and ShuibBasri, “Twitter Sentiment Analysis”, 2014 International Conference on Information Technology andMultimedia (ICIMU), Putrajaya, Malaysia November 18 – 20, 2014.
[10] V.M. KPeddimeti and P.Chintalapood, “Domain Adaption in sentiment analysis of twitter”, in Analyzing Microtext Workshop, AAAI 2011.
[11] A.Pak and P.Paraobek, “Twitter as a corpus for sentiment analysis and opinion mining”,in Proceedings of LREC, vol. 2010, 2010.



